Hadoop Namenode và Datanode là hai thành phần cốt lõi trong kiến trúc HDFS (Hadoop Distributed File System), đóng vai trò quan trọng trong việc lưu trữ và quản lý dữ liệu. Hiểu rõ sự khác biệt giữa Namenode và Datanode là chìa khóa để vận hành hệ thống Hadoop hiệu quả. Bài viết này sẽ phân tích chi tiết về vai trò, chức năng, và mối quan hệ giữa hai thành phần này.
Vai Trò của Namenode trong Hadoop
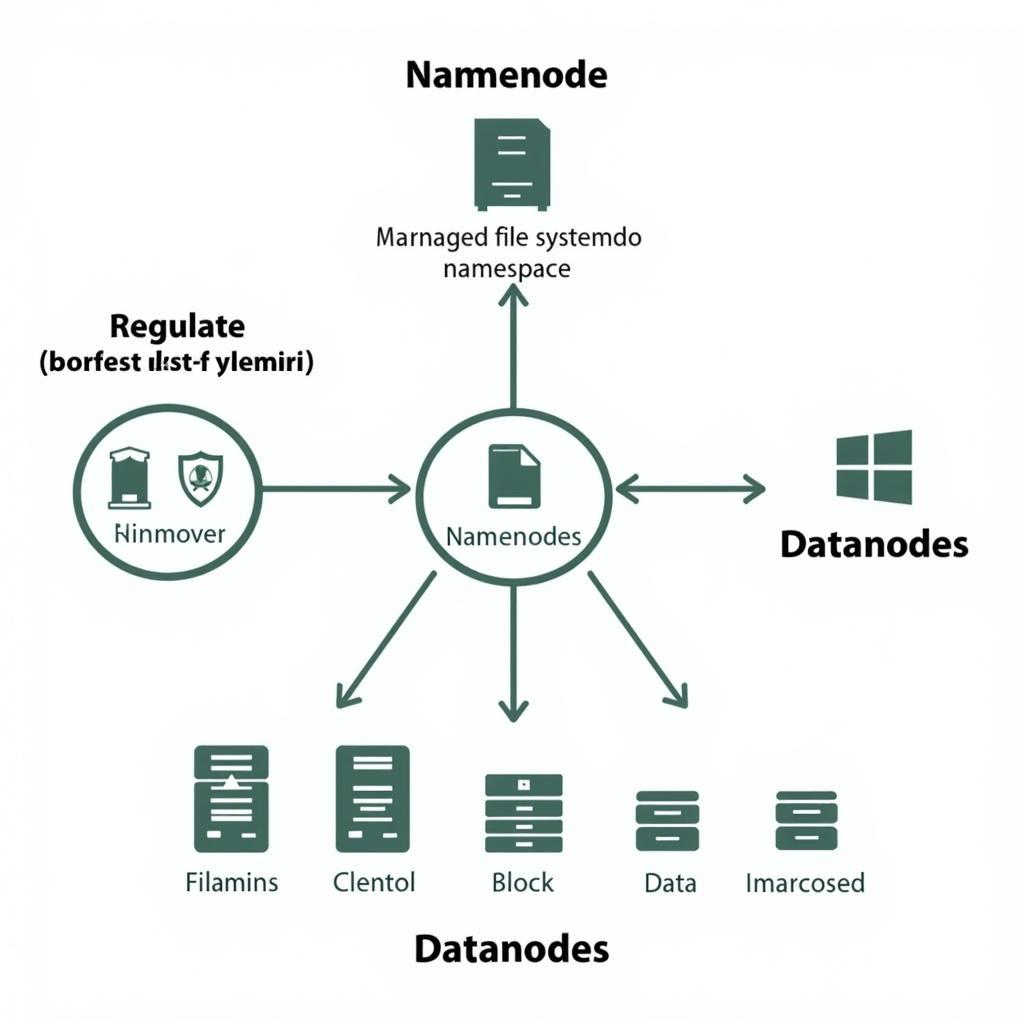
Namenode hoạt động như “người quản lý” của HDFS, giám sát toàn bộ hệ thống file. Nó lưu trữ metadata của tất cả các file và thư mục, bao gồm tên file, kích thước, quyền truy cập, và vị trí của các block dữ liệu trên các Datanode. Namenode không lưu trữ dữ liệu thực tế, mà chỉ lưu trữ thông tin về dữ liệu. Điều này giúp Namenode có thể nhanh chóng định vị và truy xuất dữ liệu khi cần.
Chức Năng Chính của Namenode
- Quản lý Namespace: Namenode duy trì một namespace duy nhất cho toàn bộ hệ thống file, đảm bảo tính nhất quán và toàn vẹn của dữ liệu.
- Điều phối Truy Cập Dữ Liệu: Khi người dùng muốn truy cập một file, Namenode sẽ cung cấp vị trí của các block dữ liệu trên các Datanode.
- Quản Lý Block Dữ Liệu: Namenode theo dõi trạng thái của các block dữ liệu trên các Datanode, đảm bảo dữ liệu được phân phối và sao chép đúng cách.
- Xử Lý Lỗi Datanode: Khi một Datanode gặp sự cố, Namenode sẽ phát hiện và thực hiện các biện pháp phục hồi dữ liệu, đảm bảo tính sẵn sàng cao của hệ thống.
 Chức năng của Namenode
Chức năng của Namenode
Vai Trò của Datanode trong Hadoop
Datanode là “kho chứa” dữ liệu thực tế trong HDFS. Mỗi Datanode lưu trữ một phần của dữ liệu dưới dạng các block. Chúng nhận lệnh từ Namenode để thực hiện các thao tác đọc, ghi, và sao chép dữ liệu. Datanode cũng định kỳ gửi báo cáo “heartbeat” đến Namenode để thông báo trạng thái hoạt động của mình.
Chức Năng Chính của Datanode
- Lưu Trữ Dữ Liệu: Datanode lưu trữ các block dữ liệu và đảm bảo tính toàn vẹn của dữ liệu được lưu trữ.
- Thực Hiện Thao Tác Đọc/Ghi: Datanode nhận lệnh từ Namenode và client để thực hiện các thao tác đọc và ghi dữ liệu.
- Sao Chép Dữ Liệu: Datanode sao chép các block dữ liệu theo chỉ thị của Namenode để đảm bảo tính dự phòng và khả năng phục hồi dữ liệu.
- Báo Cáo Trạng Thái: Datanode định kỳ gửi báo cáo heartbeat đến Namenode để thông báo trạng thái hoạt động và dung lượng lưu trữ còn trống.
So Sánh Namenode và Datanode
| Đặc điểm | Namenode | Datanode |
|---|---|---|
| Chức năng | Quản lý metadata | Lưu trữ dữ liệu |
| Số lượng | Một (hoặc một active và một standby) | Nhiều |
| Điểm lỗi | Điểm lỗi đơn (single point of failure) | Có khả năng chịu lỗi |
| Dung lượng lưu trữ | Thấp | Cao |
| Tương tác | Nhận yêu cầu từ client và điều phối Datanode | Nhận lệnh từ Namenode và client |
Hadoop Namenode High Availability
Để khắc phục điểm yếu “single point of failure” của Namenode, Hadoop cung cấp cơ chế High Availability, cho phép có một Namenode dự phòng (standby) luôn sẵn sàng tiếp quản khi Namenode chính gặp sự cố.
Kết luận
Hadoop Namenode và Datanode là hai thành phần không thể thiếu trong hệ thống HDFS. Namenode quản lý metadata và điều phối truy cập dữ liệu, trong khi Datanode lưu trữ dữ liệu thực tế. Hiểu rõ sự khác biệt giữa Namenode vs Datanode giúp tối ưu hóa hiệu suất và đảm bảo tính ổn định của hệ thống Hadoop.
FAQ
- Namenode lưu trữ dữ liệu ở đâu? Namenode lưu trữ metadata trên đĩa cứng cục bộ và trong bộ nhớ.
- Nếu Namenode bị lỗi thì sao? Nếu Namenode bị lỗi, hệ thống HDFS sẽ không hoạt động. Vì vậy, cần có cơ chế High Availability.
- Datanode có thể lưu trữ bao nhiêu dữ liệu? Dung lượng lưu trữ của Datanode phụ thuộc vào cấu hình phần cứng.
- Làm thế nào để thêm một Datanode mới vào cluster? Cần cấu hình Datanode mới và đăng ký nó với Namenode.
- Heartbeat là gì? Heartbeat là tín hiệu mà Datanode gửi định kỳ đến Namenode để thông báo trạng thái hoạt động.
- Số lượng Datanode tối đa trong một cluster là bao nhiêu? Số lượng Datanode phụ thuộc vào nhu cầu lưu trữ và khả năng xử lý của cluster.
- Sự khác biệt giữa block và file trong HDFS là gì? File được chia thành các block để lưu trữ trên các Datanode khác nhau.
Mô tả các tình huống thường gặp câu hỏi.
Một số câu hỏi thường gặp liên quan đến sự khác biệt giữa Namenode và Datanode bao gồm việc tìm hiểu vai trò của từng thành phần, cách chúng tương tác với nhau, và cách xử lý khi gặp sự cố. Người dùng cũng thường quan tâm đến việc cấu hình và tối ưu hóa Namenode và Datanode để đạt hiệu suất tốt nhất.
Gợi ý các câu hỏi khác, bài viết khác có trong web.
Bạn có thể tìm hiểu thêm về kiến trúc HDFS, cơ chế sao chép dữ liệu, và các thành phần khác của Hadoop.