Understanding the difference between 1 byte and 2 bytes in Japanese character encoding is crucial for anyone working with Japanese text, be it website development, software programming, or even simple text processing. This distinction affects how text is stored, displayed, and processed, and overlooking it can lead to unexpected issues.
What are Bytes and How Do They Relate to Japanese Characters?
A byte is a fundamental unit of data in digital systems. It’s essentially a sequence of eight bits that can represent a character, a number, or a symbol. In simpler terms, think of it as a tiny box that can hold one letter or symbol. The 1 byte vs 2 bytes distinction in Japanese arises because the Japanese writing system uses a vast number of characters, more than can be represented by a single byte.
Initially, computers used single-byte encoding systems like ASCII, which could only handle 128 characters. This was sufficient for English but not for languages like Japanese, which utilize thousands of characters including hiragana, katakana, and kanji.
This limitation led to the development of multi-byte encoding systems, allowing for the representation of a much wider range of characters. This is where 2-byte encoding comes into play, enabling the representation of the full spectrum of Japanese characters.
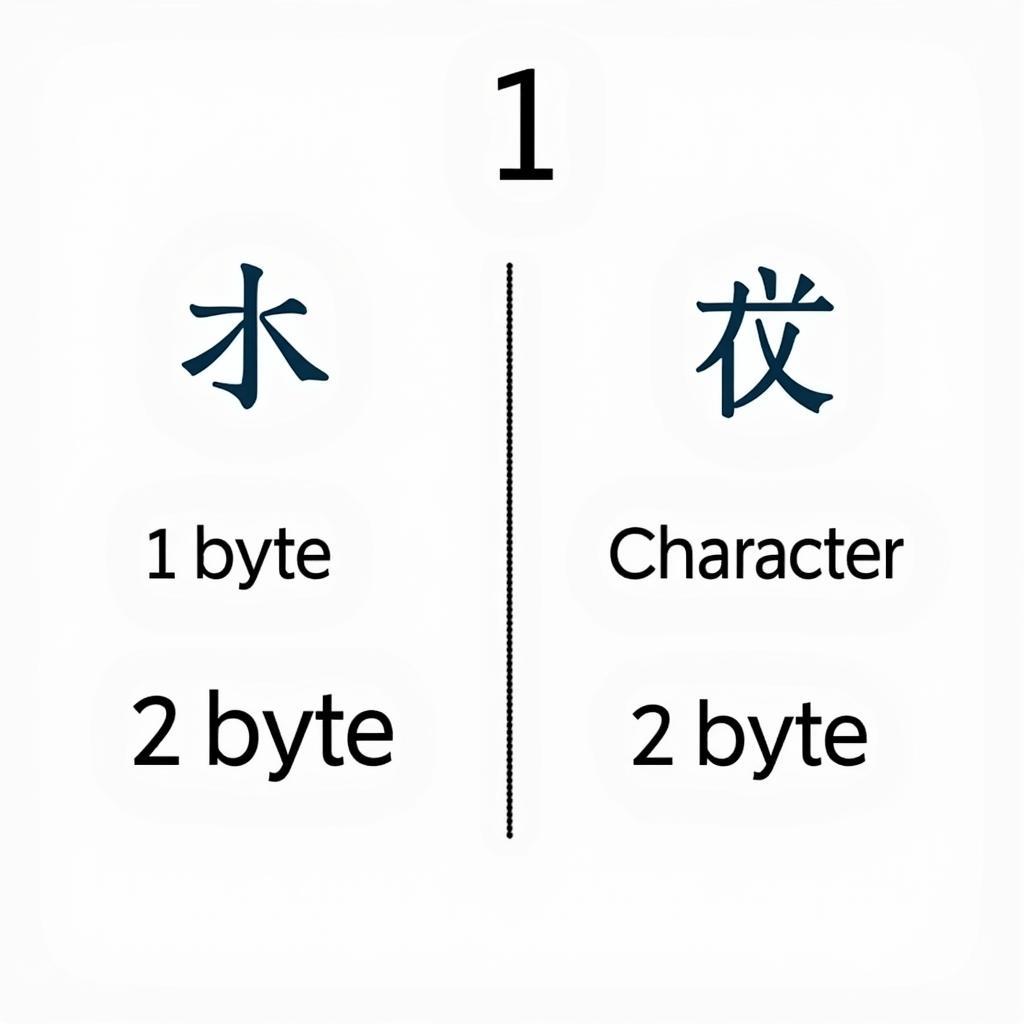 So sánh Biểu diễn Ký tự Tiếng Nhật 1 Byte và 2 Byte
So sánh Biểu diễn Ký tự Tiếng Nhật 1 Byte và 2 Byte
1-Byte Characters: Limited Scope
1-byte encoding, also known as half-width characters (半角 – Hankaku), is mainly used for representing basic Latin characters, numbers, and symbols. While it can represent a limited set of katakana characters, it cannot represent kanji or the full range of symbols required for proper Japanese text. Using 1-byte encoding for Japanese often leads to character corruption or display issues, making text unreadable.
2-Byte Characters: Enabling Full Japanese Text Representation
2-byte encoding, also known as full-width characters (全角 – Zenkaku), is essential for displaying and processing Japanese text correctly. It allows for the representation of hiragana, katakana, kanji, and a wide array of symbols. This ensures that the richness and nuances of the Japanese language can be preserved in digital formats.
Why is Understanding this Difference Important?
The 1 byte vs 2 bytes difference is crucial for various reasons:
- Data Integrity: Using the wrong encoding can corrupt Japanese text, making it unreadable.
- Software Development: Programmers working with Japanese text need to be aware of encoding issues to ensure proper functionality.
- Website Development: Incorrect encoding can lead to display issues on websites, making them inaccessible to Japanese users.
- Data Analysis: Understanding encoding is essential for accurately analyzing Japanese text data.
 Ảnh hưởng của Việc Mã hóa Sai Ký tự Tiếng Nhật
Ảnh hưởng của Việc Mã hóa Sai Ký tự Tiếng Nhật
“Understanding the nuances of character encoding is fundamental for anyone working with Japanese text,” says Dr. Haruka Sato, a leading expert in computational linguistics. “Failing to address this properly can lead to significant technical issues and miscommunication.”
How to Choose the Right Encoding
UTF-8 is the recommended encoding for Japanese text. It’s a variable-width encoding, meaning it can use 1 to 4 bytes to represent characters. This makes it highly versatile and efficient for handling a wide range of languages, including Japanese.
Practical Implications of 1 Byte vs 2 Bytes in Japanese
Imagine trying to send a message to a Japanese friend containing kanji characters, but your system only supports 1-byte encoding. The message will likely be garbled and unreadable on their end. Similarly, a website using the wrong encoding may display incorrectly for Japanese users, hindering their experience.
“In the globalized world, ensuring correct character encoding is not just a technical detail, but a key factor in effective communication,” adds Mr. Kenji Tanaka, a seasoned software engineer with extensive experience in internationalization.
Conclusion
The distinction between 1 byte and 2 bytes in Japanese text is critical for ensuring accurate representation, processing, and display of Japanese characters. Using the correct encoding, preferably UTF-8, is essential for avoiding technical issues and facilitating clear communication. By understanding these fundamental concepts, you can effectively work with Japanese text in various digital environments.
FAQ
- What is the difference between 1 byte and 2 bytes in Japanese?
- Why is UTF-8 recommended for Japanese text?
- What problems can arise from using the wrong encoding?
- What are half-width and full-width characters?
- How can I check the encoding of a text file?
- What is the best practice for handling Japanese text in website development?
- What are some common encoding errors encountered with Japanese text?
Khi cần hỗ trợ hãy liên hệ Số Điện Thoại: 02838172459, Email: truyenthongbongda@gmail.com Hoặc đến địa chỉ: 596 Đ. Hậu Giang, P.12, Quận 6, Hồ Chí Minh 70000, Việt Nam. Chúng tôi có đội ngũ chăm sóc khách hàng 24/7.